常见的无监督学习算法: 降维: – 主成分分析PCA降维处理 聚类: – K-means(k均值聚类) 2、主成分分析 应用PCA实现特征的降维 ·定义:高维数据转化为低维数据的过程,在此过程中可能会舍弃原有数据、创造新的...
”k-means k-means算法 mean ns pca 学习 无监督学习 机器学习 监督学习 聚类“ 的搜索结果
K-means算法属于八大经典的机器学习算法中的其中一种,是一种无监督的聚类算法。其中无监督是机器学习领域中一个专业名词,和有监督是相对的,两者最本质的区别就在于研究的样本是否包含标签。比如猫狗分类这个...
K-均值聚类 (K-Means Clustering)是一种经典的无监督学习算法,用于将数据集分成K个不同的簇。其核心思想是将数据点根据距离的远近分配到不同的簇中,使得簇内的点尽可能相似,簇间的点尽可能不同。
K-means聚类是一种广泛用于数据挖掘和机器学习的划分方法,它的目标是将n个观测点划分到k个簇中,使得每个点都属于离它最近的均值(即簇中心)对应的簇,从而使簇内的点尽可能地相似(即内聚度高),而不同簇的点尽...
机器学习课程作业_基于matlab实现K-means聚类算法并应用于压缩图像(matlab完整源码).zip 机器学习课程作业_基于matlab实现K-means聚类算法并应用于压缩图像(matlab完整源码).zip 机器学习课程作业_基于matlab实现K-...

聚类算法是一种无监督学习算法,可以将相似的数据点分组成簇,是数据挖掘和机器学习领域中的重要技术之一。常用的聚类算法包括上文的K-Means、层次聚类、DBSCAN等。聚类算法的优点在于可以自动发现数据的内在结构和...
聚类分析是一种无监督学习方法,用于将数据集中的样本分组成若干个簇(cluster)。K-means是最广泛使用的聚类算法之一,其核心思想是将数据点分配到K个簇中,使得每个点到其簇中心的距离之和最小。在本文中,我们将...
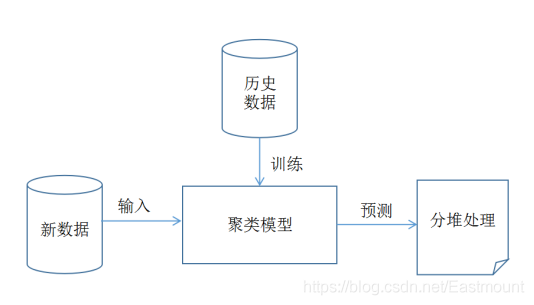
python实现机器学习K-means聚类算法源代码+数据,对数据进行聚类并绘图,k-means算法对大数据薪资情况的聚类分析 简介 本项目使用python实现机器学习K-means聚类算法,对数据进行聚类并绘图。 数据使用了boss直聘...
作为一种无监督学习算法,K-均值聚类可以自动将相似的数据点归为一类,而无需事先标注数据,在数据挖掘、客户细分、图像分割等领域有广泛应用。下面就让我们一起来了解K-均值算法的基本原理、优缺点以及Python实现吧。
博客标题:深入解析K-Means聚类算法:...最后,通过可视化技术和聚类结果分析,加深读者对K-Means算法的理解,并提供新样本预测的方法。无论是数据科学新手还是希望深化聚类技能的研究者,本文都提供了宝贵的知识资源。
基于半监督K-means的主动学习聚类算法 ,孙凯,孟祥武,针对K-means算法对初始聚类中心敏感,针对不规则聚类簇效果较差的缺点,提出了一种基于半监督K-means的主动学习算法。为了针对指定的k
K-Means算法是典型的基于距离的非层次聚类算法,在最小化误差函数的基础上将数据划分为预定的类数K,采用距离作为相似性的评价指标,即认为两个对象的距离越近其相似度就越大。
为了解决 K-均值聚类算法的缺点,有一些改进的版本,如:加权 K-均值聚类(Weighted K-means clustering)、层次 K-均值...K-均值聚类(K-means clustering)是一种常用的无监督学习算法,用于将数据分为不同的聚类。
【零基础学机器学习 15】 K-均值聚类( K-means)算法:类型、工作原理及代码实战 https://blog.csdn.net/shangyanaf/article/details/133243206
这里需要引入一个新的概念就是K距离,我们将某个对象确定为核心对象后,计算每一个点到该点的距离,然后找到突变点,以突变点上一个点的距离作为我们半径r的设定距离。在上图中,算法首先确定了一个核心对象即为A,...
不限次数、免费不需要注册。单次不要传太大的文件,防止中断导致无法转换,上传之后过一段时间,右侧就会出现转换完成的word文档。需要注意的是180s之后还没有转换出来就是类容太多,拆分小一点转换即可。
K-MEANS算法是聚类问题中,最简单,也是最实用的一个算法 基本概念 一个数据放进来,需要指定K值,来声明要得到簇的个数 质心:一个簇的数据均值,即向量各维取平均即可(迭代时使用) 距离的度量:常用欧几里得距离...
K-means聚类PPT,讲课实用课件。共包括算法原理、算法流程、实例讲解、应用场景、算法总结、改进算法几个内容。
无监督学习–K-means聚类算法学习 介绍:k-means算法以k为参数,把n个对象分成k个簇,使簇内具有较高的相似度,而簇间的相似度比较低。 其处理过程如下: 1、随机选择k个点作为初始的聚类中心; 2、对于剩下的点,...
本文为大家分享了Python机器学习之K-Means聚类的实现代码,供大家参考,具体内容如下 1.K-Means聚类原理 K-means算法是很典型的基于距离的聚类算法,采用距离作为相似性的评价指标,即认为两个对象的距离越近,其...
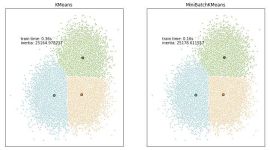

本节用Python实现K-Means算法,对未标注的数据进行聚类。主要参考《机器学习实战》—— Peter Harrington著。 导航K-Means简介代码实现(一)数据集读入(二)距离计算(三)构建随机质心(四)数据聚类(五)完整...
无监督学习-kmeans聚类算法及手动实现jupyter代码.ipynb

然而在机器学习的任务中,还存在另外一种训练样本的标签是未知的,即“无监督学习”。此类任务中研究最多、应用最广泛的是“聚类”(clustering),常见的无监督学习任务还有密度估计、异常检测等。本文将首先介绍...
推荐文章
- 大数据和云计算哪个更简单,易学,前景比较好?_大数据和云计算哪个好-程序员宅基地
- python操作剪贴板错误提示:pywintypes.error: (1418, 'GetClipboardData',线程没有打开的剪贴板)...-程序员宅基地
- IOS知识点大集合_ios /xmlib.framework/headers/xmmanager.h:66:32: ex-程序员宅基地
- Android Studio —— 界面切换_android studio 左右滑动切换页面-程序员宅基地
- 数据结构(3):java使用数组模拟堆栈-程序员宅基地
- Understand_6.5.1175::New Project Wizard_understand 6.5.1176-程序员宅基地
- 从零开始带你成为MySQL实战优化高手学习笔记(二) Innodb中Buffer Pool的相关知识_mysql_global_status_innodb_buffer_pool_reads-程序员宅基地
- 美化上传文件框(上传图片框)_文件上传框很丑-程序员宅基地
- js简单表格操作_"var str = '<table border=\"5px\"><tr><td>序号</td><-程序员宅基地
- Power BI销售数据分析_powerbi汇总销售人员业绩包括无销售记录的人-程序员宅基地